当您从在类中写一个字符串字面量时,JVM将首先检查该字符串是否已存在于字符串常量池中,如果存在,JVM 将返回对现有字符串对象的引用,而不是创建新对象。我们通过一个例子更好的来理解。
比如下面的代码:
String s1 = "Harry Potter";
String s2 = "The Lord of the Rings";
String s3 = "Harry Potter";
在这段代码中,JVM 将创建一个值为“Harry Potter”的字符串对象,并将其存储在字符串常量池中。s1和s3都将是对该单个字符串对象的引用。
如果s2的字符串内容“The Lord of the Rings”不存在于池中,则在字符串池中生成一个新的字符串对象。

两种创建字符串方式
在 Java 编程语言中有两种创建 String 的方法。第一种方式是使用String Literal字符串字面量的方式,另一种方式是使用new关键字。他们创建的字符串对象是都在常量池中吗?
- 字符串字面量的方式创建
String s1 = "Harry Potter";
String s2 = "The Lord of the Rings";
String s3 = "Harry Potter";
new关键字创建
String s4 = new String("Harry Potter");
String s5 = new String("The Lord of the Rings");
我们来比较下他们引用的是否是同一个对象:
s1==s3 //真
s1==s4 //假
s2==s5 //假
使用 == 运算符比较两个对象时,它会比较内存中的地址。
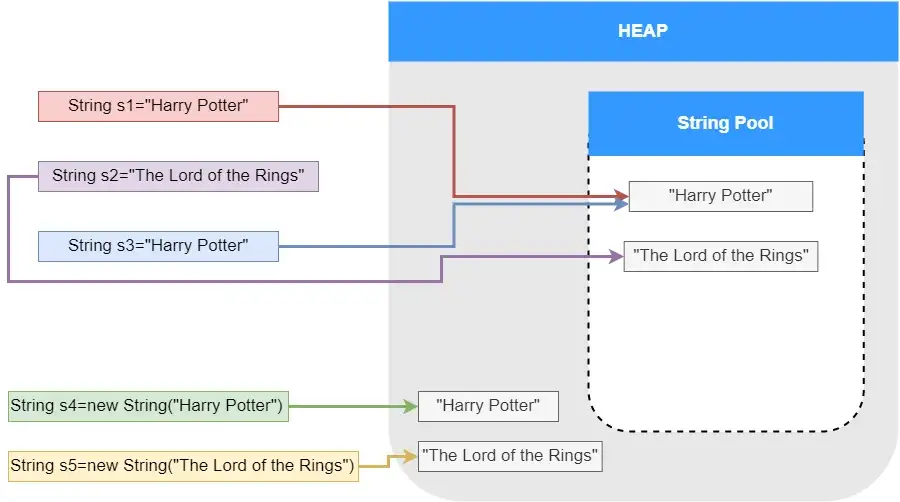
正如您在上面的图片和示例中看到的,每当我们使用new运算符创建字符串时,它都会在 Java 堆中创建一个新的字符串对象,并且不会检查该对象是否在字符串常量池中。
那么我现在有个问题,如果是字符串拼接的情况,又是怎么样的呢?
字符串拼接方式
前面讲清楚了通过直接用字面量的方式,也就是引号的方式和用new关键字创建字符串,他们创建出的字符串对象在堆中存储在不同的地方,那么我们现在来看看用+这个运算符拼接会怎么样。
例子1
public static void test1() {
// 都是常量,前端编译期会进行代码优化
// 通过idea直接看对应的反编译的class文件,会显示 String s1 = "abc"; 说明做了代码优化
String s1 = "a" + "b" + "c";
String s2 = "abc";
// true,有上述可知,s1和s2实际上指向字符串常量池中的同一个值
System.out.println(s1 == s2);
}
- 常量与常量的拼接结果在常量池,原理是编译期优化。
例子2
public static void test5() {
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true 编译期优化
System.out.println(s3 == s5); // false s1是变量,不能编译期优化
System.out.println(s3 == s6); // false s2是变量,不能编译期优化
System.out.println(s3 == s7); // false s1、s2都是变量
System.out.println(s5 == s6); // false s5、s6 不同的对象实例
System.out.println(s5 == s7); // false s5、s7 不同的对象实例
System.out.println(s6 == s7); // false s6、s7 不同的对象实例
}
- 只要其中有一个是变量,结果就在堆中, 变量拼接的底层原理其实是
StringBuilder。
例子3:
public void test6(){
String s0 = "beijing";
String s1 = "bei";
String s2 = "jing";
String s3 = s1 + s2;
System.out.println(s0 == s3); // false s3指向对象实例,s0指向字符串常量池中的"beijing"
String s7 = "shanxi";
final String s4 = "shan";
final String s5 = "xi";
String s6 = s4 + s5;
System.out.println(s6 == s7); // true s4和s5是final修饰的,编译期就能确定s6的值了
}
- 不使用final修饰,即为变量。如s3行的s1和s2,会通过new StringBuilder进行拼接
- 使用final修饰,即为常量。会在编译器进行代码优化。
妙用String.intern() 方法
前面提到new关键字创建出来的字符串对象以及某些和变量进行拼接不会在字符串常量池中,而是直接在堆中新建了一个对象。这样不大好,做不到复用,节约不了空间。那有什么好办法呢?intern()就派上用场了,这个非常有用。
intern()方法的作用可以理解为主动将常量池中还没有的字符串对象放入池中,并返回此对象地址。
String s6 = new String("The Lord of the Rings").intern();

s2==s6 //真
s2==s5 //假
字符串常量池有多大?
关于字符串常量池究竟有多大,我也说不上来,但是讲清楚它底层的数据结构,也许你就明白了。
字符串常量池是一个固定大小的HashTable,哈希表,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降。
使用-XX:StringTablesize可设置StringTable的长度
- 在jdk6中
StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。StringTable Size设置没有要求 - 在jdk7中,StringTable的长度默认值是
60013,StringTable Size设置没有要求
● 在jdk8中,设置StringTable长度的话,1009是可以设置的最小值
字符串常量池的优缺点
字符串池的优点
- 提高性能。由于 JVM 可以返回对现有字符串对象的引用而不是创建新对象,因此使用字符串池时字符串操作更快。
- 共享字符串,节省内存。字符串池允许您在不同的变量和对象之间共享字符串,通过避免创建不必要的字符串对象来帮助节省内存。
字符串池的缺点
- 它有可能导致性能下降。从池中检索字符串需要搜索池中的所有字符串,这可能比简单地创建一个新的字符串对象要慢。如果程序创建和丢弃大量字符串,则尤其如此,因为每次使用字符串时都需要搜索字符串池。
总结
其实在 Java 7 之前,JVM将 Java String Pool放置在PermGen空间中,它具有固定大小——它不能在运行时扩展,也不符合垃圾回收的条件。在PermGen(而不是堆)中驻留字符串的风险是,如果我们驻留太多字符串,我们可能会从 JVM 得到一个OutOfMemory错误。从 Java 7 开始,Java String Pool存放在Heap空间,由 JVM进行垃圾回收。这种方法的优点是降低了OutOfMemory错误的风险,因为未引用的字符串将从池中删除,从而释放内存。
现在通过本文的学习,你该知道如何更好的创建字符串对象了吧。

