随着业务发展,我们的系统可能面临着改造升级。改造过程中往往避免不了数据模型的变动,这时候需要将老表老模型迁移到新表新模型,并且还要保证历史数据的迁移以及映射。
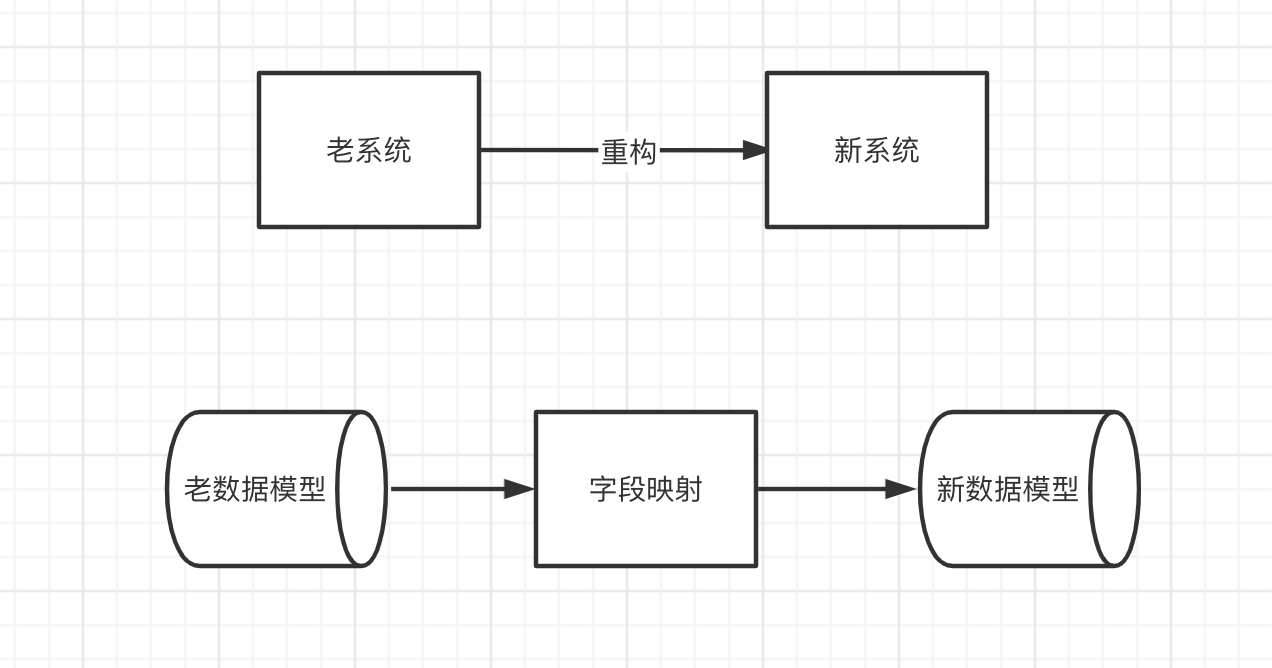
这就带来了一个问题,老表老模型如何迁移到新表新模型,以下是常用的两种方案
| 方案 | 是否支持回切 | 优点 | 缺点 |
|---|---|---|---|
| 双写 | 是 | 1.简单易操作2.无需中间件支持3.无延迟 | 1.对业务侵入大,需要在新老系统维护对应的数据同步逻辑 |
| 监听binlog,数据双向同步 | 是 | 1.对业务0侵入2.方便定制化逻辑 | 1.需要中间件支持2.具有一定延迟性 |
数据同步很少有只同步单向的。除非是数据库的压力大了要将表拆分出,这时候存在表模型一样的情况。更常见的是在灰度阶段,新老系统同时都在运行,这时候就需要同时维护新老数据,因此需要采取双向同步的策略。
双写
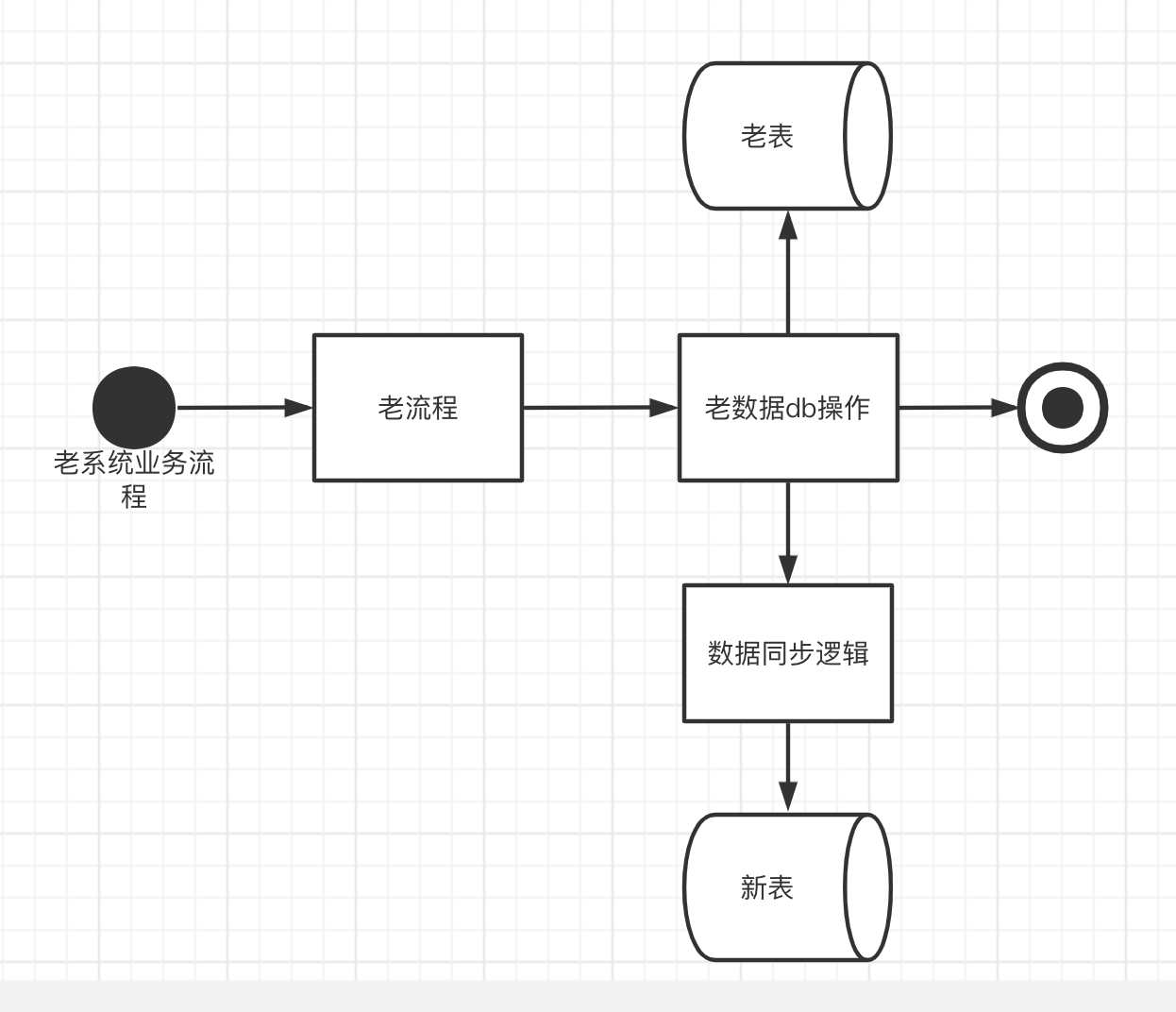
数据同步又分为增量数据同步、存量数据同步。一般来说我们会在老系统中所有更新表的地方将数据同步逻辑开发好,先上线,同步几天存量数据,然后选择某上线后的一天作为存量数据的截止时间,这是为了防止存量数据和增量数据中间有数据空洞,造成数据丢失的情况
增量数据
同步增量数据有几个步骤
- 将老系统中所有新增、更新的地方都写上数据同步逻辑
- 在同步数据的时候,除了新老模型字段的映射逻辑以外,当操作是新增的时候,直接新增新表数据,当操作是更新的时候,如果新表没有对应信息,那么查一下老表的数据,然后映射到新模型数据结构再新增到新表
- 更新新模型的时候可能存在并发问题,这时候我们插入的时候要检查时间戳或者版本号,如果库内数据早于自己,就更新,否则就丢弃。
存量数据
存量数据一般就是取数,取数有两种比较常见的方式
- 通过sql扫表,如果表比较大可以按月或者按天扫,优点是操作简单,缺点是需要人工一直介入,且扫表会对数据库造成一定压力,影响业务功能的稳定性
- 同步离线表取数,将离线表的数据发送到mq或者kafaka,消费后进行数据同步
存量数据同步的时候也需要注意的是数据的版本问题,如果不存在就新增,如果存在就判断时间戳或版本号,总之就是将最新的数据更新进去,老版本数据抛弃。
总结
从上面我们可以看出双向同步的问题就是同步代码的复用性差,业务代码内部维护的增量逻辑和存量同步的逻辑不能复用,需要重复开发。还有一个问题就是当新老模型差距较大或者新数据源的变动比较大的时候,比如从一种存储介质同步到另一种存储介质,这些复杂逻辑维护到了每个更新接口处,开发成本不可预估,因此此方案只适合公司没有中间件支持并且又要做改造的情况下使用。
ps:如果存量数据有时效性,比如一个月以前的数据不要了,并且改造的周期比较长,那么可以不需要同步存量数据,让增量数据跑一个月即可。
binlog,数据双向同步
我们都知道当数据变更的时候(新增、更新、删除),db 都会记录变更日志,并且同步到各个从库中,这个日志就是我们耳闻能详的 binlog。开源的工具主要有:Canal、otter等,基本原理就是解析binlog日志,然后发送到消息中间件,客户端消费后进行处理。
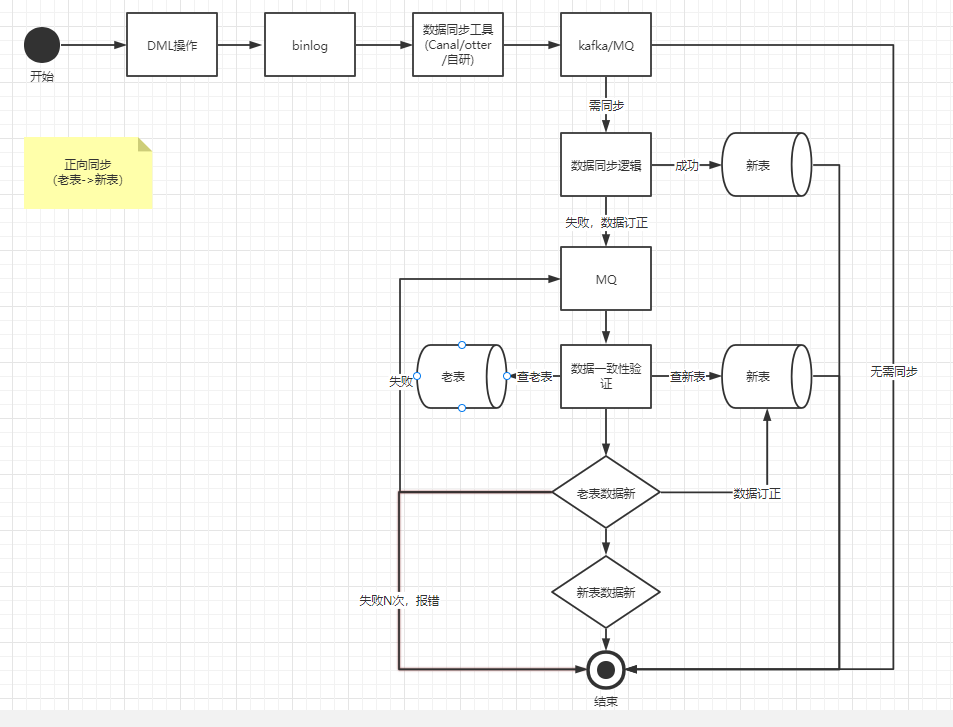
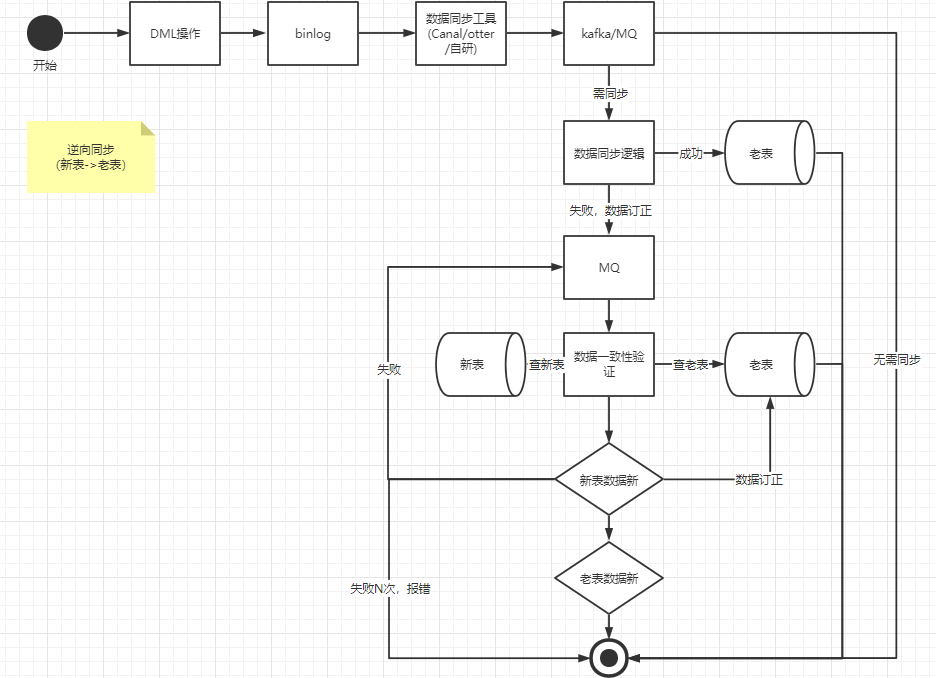
由于我们是线上新老系统一起在跑,因此我们需要进行数据双向同步,也就是正向同步:老表到新表;逆向同步:新表到老表。
老表到新表增量同步
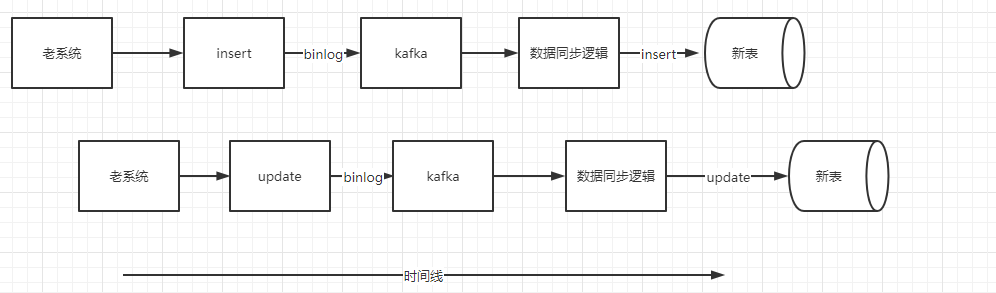
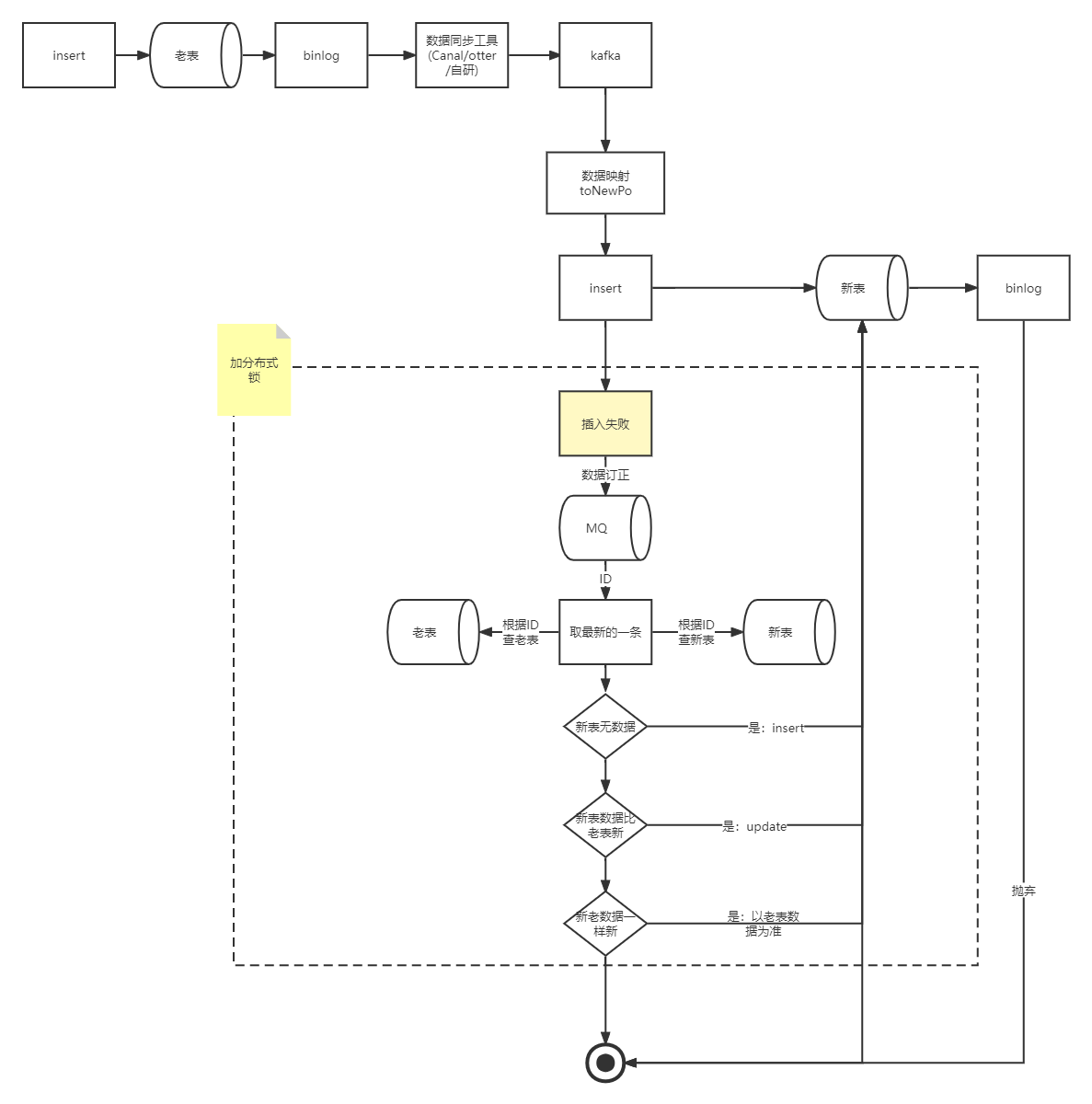
当老系统进行DML(insert、update,由于大部分业务都是采用逻辑删的情况也就是update,因此这里不考虑delete情况)操作的时候,老表会吐出相应的binlog,binlog 经过我们的数据同步工具会将对应的消息投递到kafka或者mq,在我们的 convert 数据同步逻辑内将对应的消息映射成新数据模型后,会将消息是 insert 还是 update 进行不同处理
insert
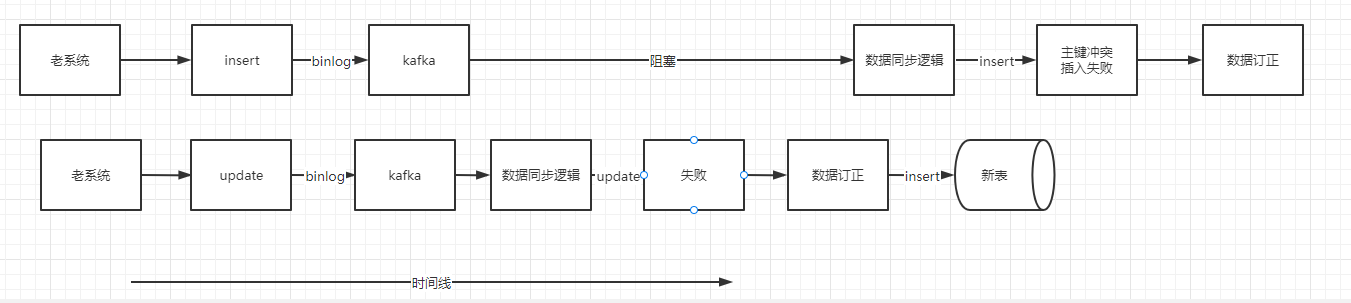
经过 convert 将消息转化成对应的新数据模型后,直接进行插入操作。这里可能会出现一些异常场景,比较常见的是 insert 操作还没插入新表,老系统就对该记录操作了一次更新,然后也吐出了一条 binlog,这时候这条 binlog 先被客户端消费,由于更新的时候如果新表内没有数据,会更新失败,更新失败后会走数据订正逻辑,数据订正的时候如果新表没有数据则会新增。这时候再操作 insert 操作就会报主键冲突。新增失败的时候也会走数据订正逻辑。
这里可能有个疑问,直接在消费到的时候根据数据的主键ID加一把分布式锁能不能解决问题。答案是不能解决,因为更新操作可能会更先被消费到,这时候还是会报主键重复,并且如果数据量大的情况下,加锁还会导致数据同步性能问题。
正常流程:
异常流程:
update
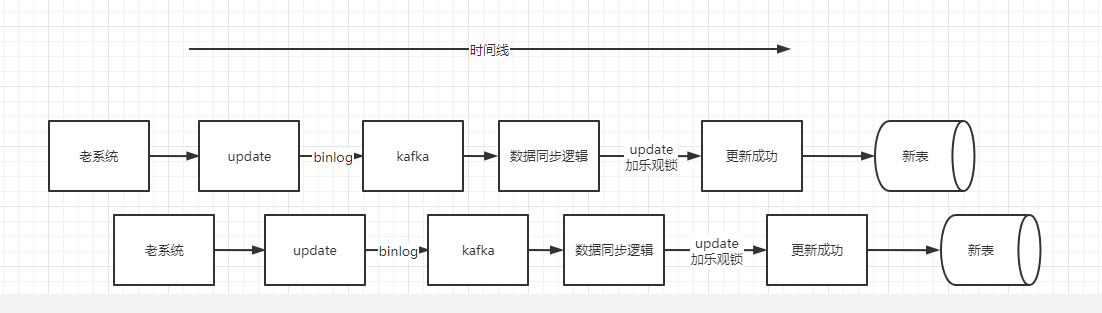
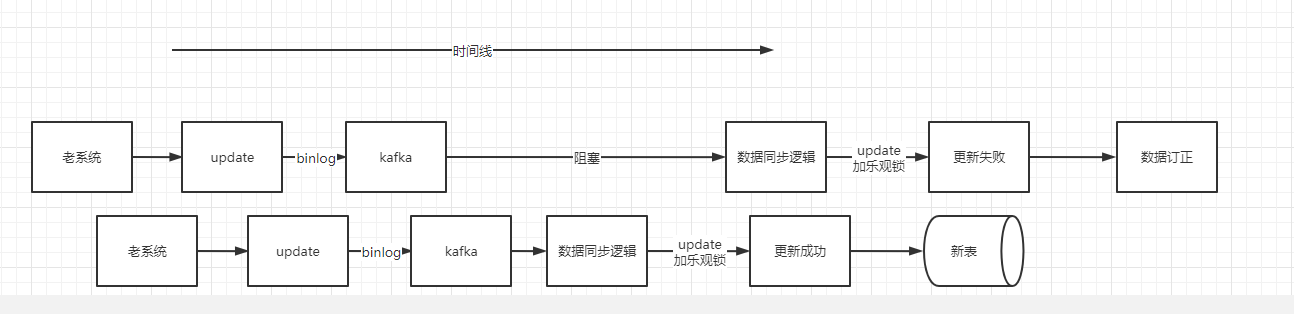
客户端收到 update 的binlog消息后,会将消息体内容经过 convert 逻辑转化成新模型,也就是数据库PO对象,然后进行 update 操作。但是不是无脑更新的,需要加个乐观锁(where update_time < #{updateTime}),如果表里数据已经比你新了,那么就不更新,更新失败,走数据订正逻辑。如果表里数据比较老,那么更新成功。
正常流程:
异常流程:
数据订正
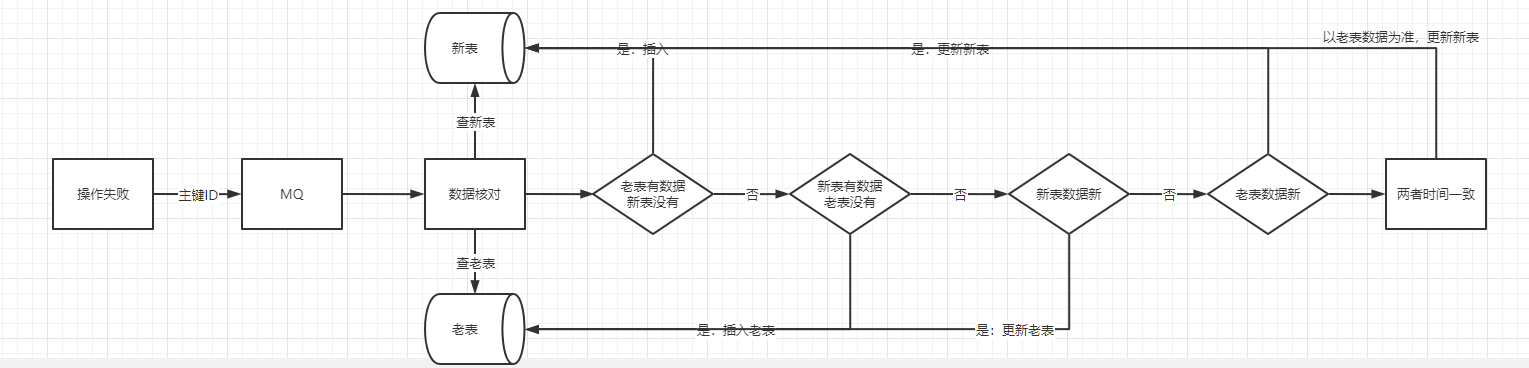
不管是 insert 操作还是 update 操作,当操作失败了以后,我们都要进行数据订正,这是为了保证最终数据一致性。
数据订正的整个过程都需要根据主键ID来进行加分布式锁,这是因为数据订正的时候是拿主键ID去新老表查数据,然后进行比对后才决定如何进行订正,这里如果不加锁的话会导致并发问题,从而订正失败。由于绝大多数的数据都是在同步流程中同步完毕,走入到数据订正的数据其实是少部分的,因此在这里加分布式锁其实是没太大影响的。
ps:新老表的主键ID要保持一致。
整体流程图
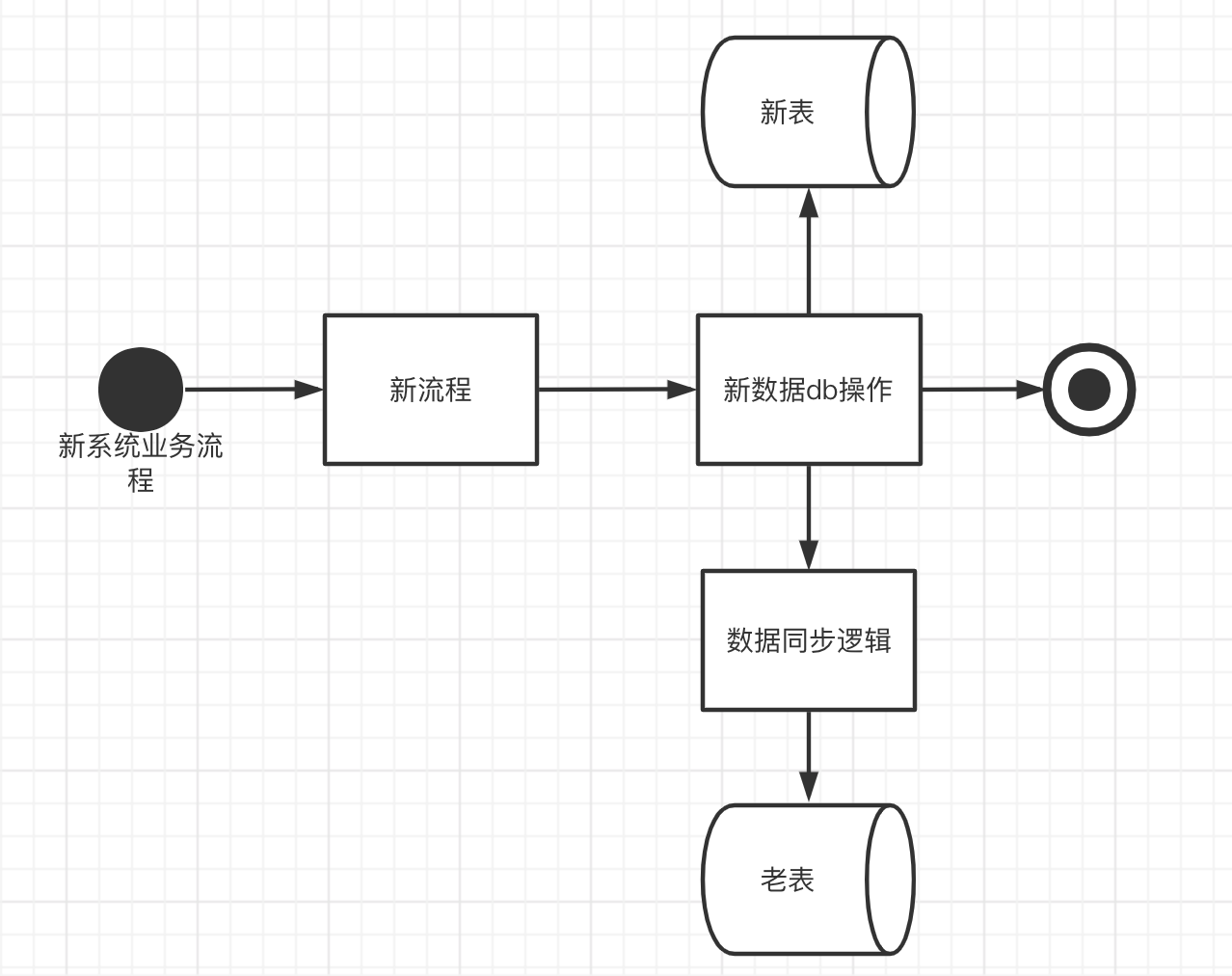
新表到老表增量同步
新表到老表也是一样的操作,无非就是双方角色互换下。新系统DML操作后,同步到老表,具体的同步逻辑还是一样的。
ps
我们都注意到,当老表同步到新表,新表同步完成后,新表也会吐出相应的 binlog,这时候客户端监听后如果按照上面的流程走下去,那么会陷入一个死循环,无限消费,那么客户端怎么监听这部分数据并且抛弃掉呢。
我们可以在新老表加个flag字段,所有业务dml操作将该字段置为1,那么数据同步客户端监听到binlog消息就进行数据同步。如果是数据同步的dml操作,将该字段置为0,那么数据同步客户端监听到binlog消息就直接抛弃掉即可。
存量同步
为了降低数据库压力,我们取存量数据是取的离线表,离线表具有延迟性,离线表存储的一半是t-1天的数据。为了防止丢数据,我们会先将老到新的增量同步逻辑先上线一两天,然后再从离线表取数,这样所有的数据都不会丢。假如我们先同步存量数据,再同步增量数据,或者增量数据同步逻辑一上线立马同步存量数据,那么t-1到t这中间就会有1天的数据缺口。
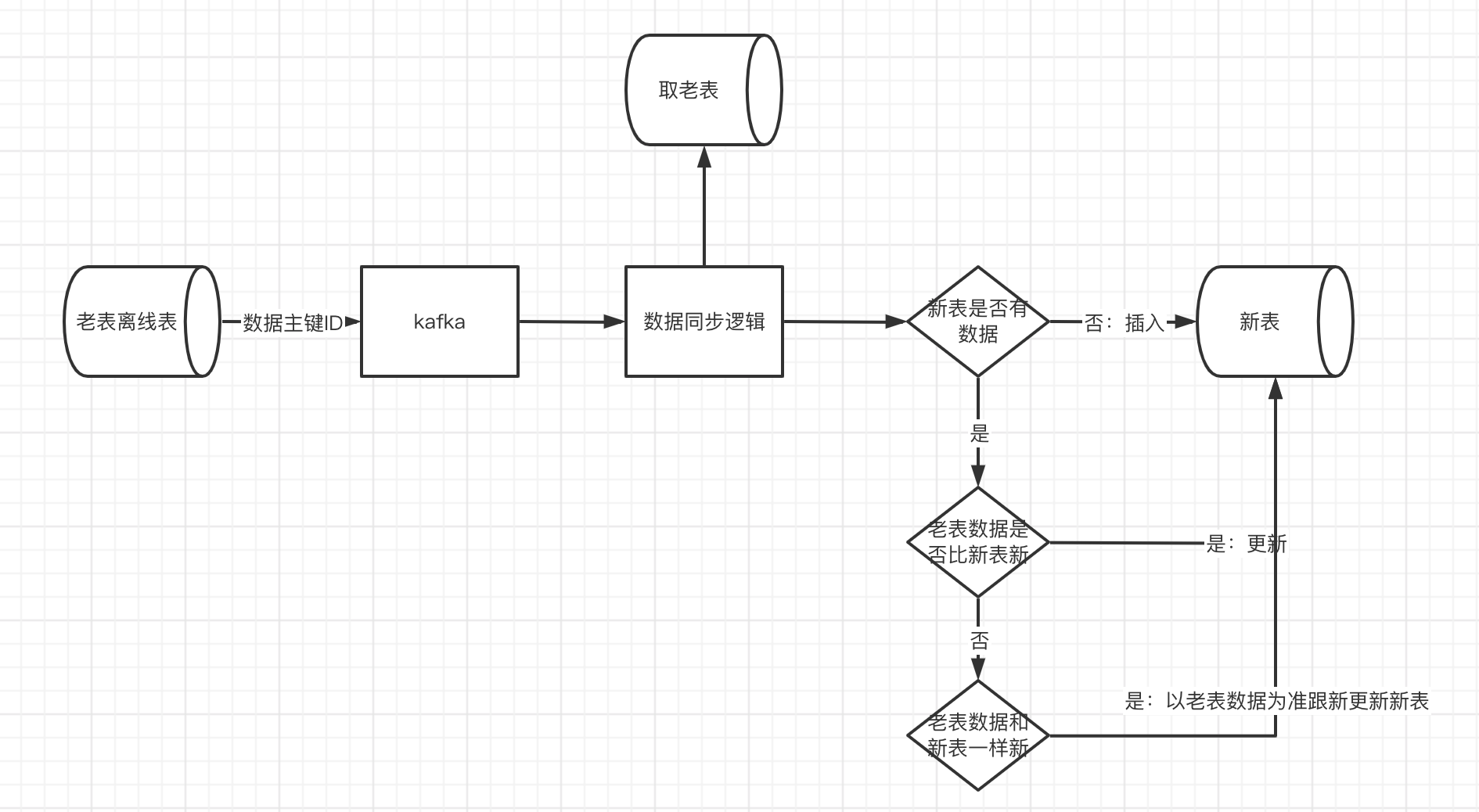
存量同步如果insert失败或者update失败和增量同步的逻辑一样,都会走数据订正逻辑,保证数据的最终一致性。
优缺点
采用binlog同步的优点就是针对所有的dml操作集中处理,解耦业务、可发挥空间大;缺点就是需要中间件支持,并且具有一定的延迟性。
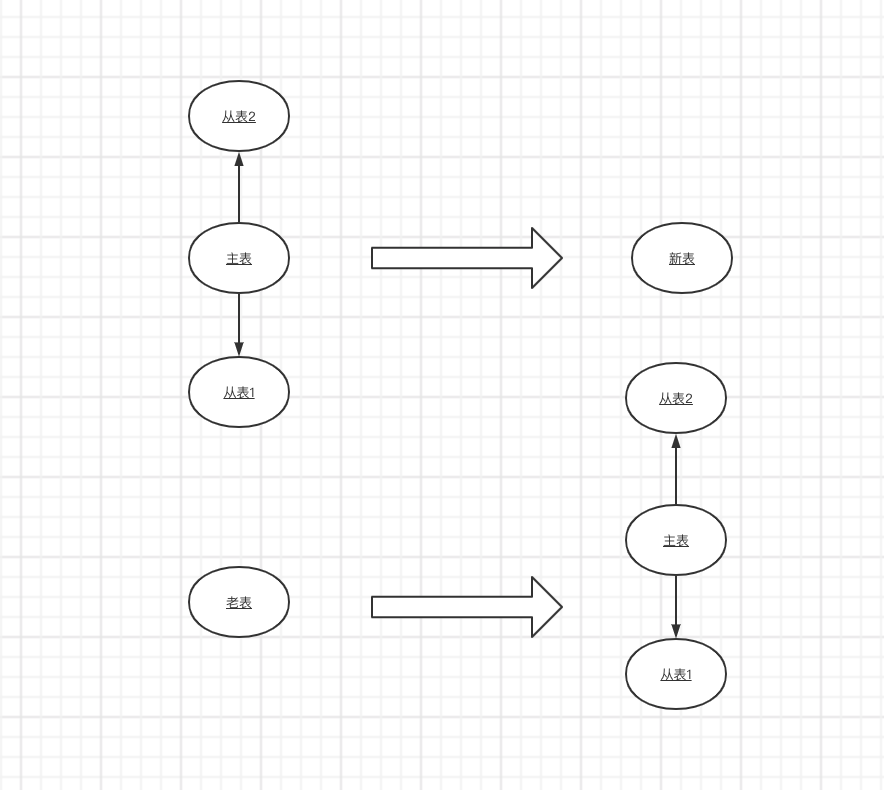
当我们老系统多张表,融合到新系统只有一张表;或者老系统一张表,拆到新系统多张表;那么这种场景就很适合用这种方式来同步,只需要在数据同步逻辑根据关联的字段查出对应的信息进行insert或者update即可。