## 创建leadership数据框
manager <- c(1,2,3,4,5)
date <-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country <- c("US","US","UK","UK","UK")
gender <- c("M","F","F","M","F")
age <- c(32,45,25,39,99)
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors = FALSE)
leadership
##创建新变量 leadership <- transform(leadership,q6=q1+q2,q7=(q1+q2)/2)
##变量的重编码
leadership <- within(leadership,{
agecat <- NA
agecat[age>75] <- "Elder"
agecat[age >=55 & age <=75] <- "Middle Aged"
agecat[age <55] <- "Young"})
leadership
##变量的重命名
install.packages("plyr")
library(plyr)
leadership <- rename(leadership, c(manager="managerID",date="testDate"))
leadership
##缺失值 缺失值是不可比较的 缺失数据需在分析前重新编码为缺失值 is.na(leadership[,6:10])
##在分析中排除缺失值 含有缺失值的算术表达式和函数的计算结果也是缺失值 sum(q4,na.rm=T)
## na.omit()移除所有含有缺失值的观测 leadership mydata <- na.omit(leadership) mydata
##日期值
as.Date()函数 将以字符串形式输入R中的日期值转化为以数值形式存储的日期变量
myformat <- "%m/%d/%y"
leadership$testDate <- as.Date(leadership$testDate,myformat)
leadership
Sys.Date()#返回当天的日期
date()#返回当前的日期和时间
DOB <- as.Date("1997-08-21")
today <- Sys.Date()
difftime(today,DOB,units="weeks")
##类型转换 is.datatype() 允许根据数据的具体类型加以不同的方式处理 as.datatype() 分析前先将数据进行转化
##数据排序 order() 默认的排序顺序--升序 在排序变量前加一个减号即可得到降序的排序结果 newdata <- leadership[order(leadership$age),] newdata
##数据集的合并 向数据框添加列 cbind() #不需要一个公共索引 向数据框添加行 rbind() #注意多余变量的处理 merge(dataframeA,dataframeB,by="") #横向合并,通过一个或多个共有变量进行联结
##数据集取子集 选入(保留)变量、剔除(丢弃)变量 #逻辑向量&比较运算符 选入观测 #subset()函数 newdata <- subset(leadership, age >= 35 | age < 24, select=q1:q4) newdata
随机抽样:从数据集中(有放回或无放回地)抽取大小为n的一个随机样本 #sample()函数 mysample <- leadership[sample(1:nrow(leadership),3,replace=F),] mysample
练习题
一.将1、2、…20构成两个5*4阶的矩阵,其中矩阵A是按列输入,矩阵B按行输入
1. 将A和B按照行合并;
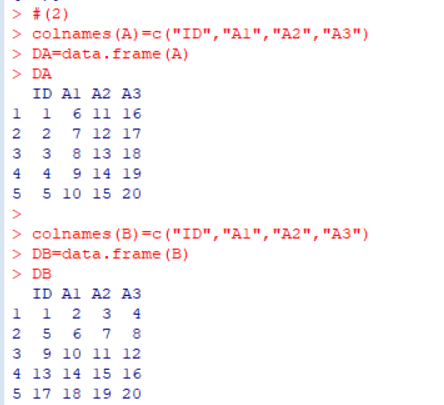
2. 将A和B转化为数据框DA和DB,并将他们的列命名为(“ID”,”A1″,”A2″,”A3″);
3. 以”ID”为条件将DA和DB进行匹配;
4. 在DA中选取“A2”列大于12且小于15的子集。
A=matrix(1:20,nrow=5,byrow=F) A B=matrix(1:20,nrow=5,byrow=T) B

#(1) rbind(A,B)

#(2)
colnames(A)=c("ID","A1","A2","A3")
DA=data.frame(A)
DA
colnames(B)=c("ID","A1","A2","A3")
DB=data.frame(B)
DB
#(3) merge(DA,DB,by="ID")

#(4) newdata=subset(DA,A2>12&A2<15,select=ID:A3) newdata

二.随机生成服从均值为2,标准差为3的正态分布的长度为5的向量x
- 将x降序排列,生成向量y
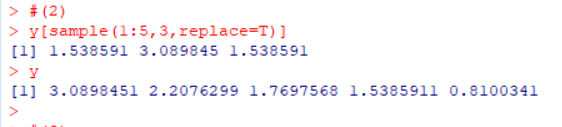
- 采用有放回抽样的方式从y中抽取3个元素
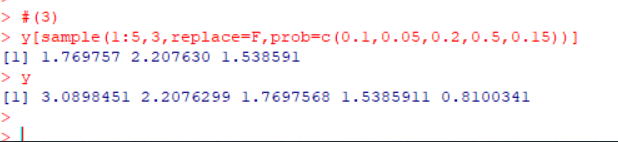
- 采用不放回抽样的方式,以概率prob=c(0.1,0.05,0.2,0.5,0.15)从中抽取3个元素。
#均值为2,标准差为3,长度为5的正态分布 x = rnorm(5,2,3) x

#(1) y=x[order(-x)] y

#(2) y[sample(1:5,3,replace=T)] y
#(3) y[sample(1:5,3,replace=F,prob=c(0.1,0.05,0.2,0.5,0.15))] y